
The Bottleneck Was Never the Code
Three months of inverting our planning-to-coding ratio



Earlier this year we kept having to re-work our AI coding assistant’s implementation of every new Bottom Sheet we were adding to the app.
We use a custom BottomSheet component on our mobile app, a wrapper around React Native Bottom Sheet that abstracts the structure and parts of the layout. Every time we asked the AI to add a new sheet, it would re-implement the library from scratch. We’d revert the change. Next session, we’d ask for a different sheet. The AI would re-implement the wrapper again. Sometimes it broke the existing ones in the process.
It wasn’t a knowledge problem, we knew exactly how we wanted these components to be implemented. We just had to repeat ourselves over and over again. Yes code was written fast but we were losing the time gained by having to explain ourselves from scratch for each new case.
The honest read on what was happening: we had no machine-readable record of how to implement these Bottom Sheets in our app, what to abstract in that wrapper and what to leave customised by the inside component. The AI couldn’t reason about a convention it had never been told about. We’d been treating it as a faster typist when its actual constraint was context.
That realization changed how we work. Three months later, we spend 80% of our time stirring feature’s scope and iterating over the specs and 20% of the time implementing, the inverse of how we used to work until AI showed up. The mechanism isn’t a smarter model or better prompts. It’s a deliberate investment in the context that agents read before they touch anything.
If writing code is no longer rationed, what is the new shape of engineering work, and what new form of debt does it produce?
This is the first piece in a five-part series on what we built, what we learned, and what we still don’t know. Today: why documentation became the infrastructure of how we work, and what we actually centralize in it.
Documentation was the bottleneck we kept ignoring
Software development has had a technical documentation problem for decades, and it’s not a tooling problem. It’s a priority problem.
The traditional flow is well-understood. A product owner writes a spec. A designer translates it into screens. An engineer translates those into code. At every handoff, context degrades. The PM didn’t realise that by adding some nice to have requirements he was adding the overhead of having to create new tables or refactor the whole data model. The designer specified a navigation that conflicts with the current navigation structure.
Documentation was supposed to prevent this but it’s a challenge to keep maintaining it. The codebase was the source of truth, and the codebase could only be read by engineers. Knowledge lived in people’s heads, surfaced in chat threads, evaporated when someone left.
When AI coding assistants arrived, we used them the obvious way: write code faster. The result was instructive. We generated more code, but the spec-to-implementation gap didn’t close. We spent less time typing and more time correcting.
The uncomfortable insight: we thought AI was all about producing code that works fast but the real challenge is engineering its context so that it produces code that works fast but that leverages your engineers knowledge and adheres to your conventions and patterns so that your codebase stays consistent and clean. This is what in turn makes your system robust and every next move easier and easier.
So we stopped optimizing for code output and started investing in documentation infrastructure.
What "80% planning, 20% coding" actually means
It doesn’t mean more meetings. It means different artifacts, maintained at a different cadence, by a different group of people.
The PM starts a session to start ideating over a new product change. He/she goes back and forth about the why, for who, the scope and finally gets to the technical spec, the "how". This is the moment where AI leverages the documentation and other artefacts to design a solution anchored in the reality of the codebase. It suggests the changes to the system documentation to deliver this feature. The engineer can review that proposal and course adjust if needed.
When implementation begins, the developer pastes a refined-issue URL into the AI tool. The agent reads the issue which contains the why, what and how all in the same place. It has highly detailed instructions that a human could almost never write which allows the coding agent to implement the changes almost in one shot. The 20% is the coding step itself, which becomes largely mechanical when the spec is precise.
This only works if the documentation is precise and current. When it drifts, agents start hallucinating confidently, which is harder to catch than a compile error. The cost of poor documentation is no longer just human confusion. It’s bad code that looks right.
That’s what we mean by context infrastructure. The docs aren’t a reference artifact. They’re the literal input agents consume before taking action.
What we centralize, and why
Our documentation lives in a single repository, a Central Hub, separate from any product code. The same hub serves multiple codebases (in our case, a backend, a mobile app and a web app). When a convention gets updated, every agent on every project picks it up immediately.
The hub holds two layers: company and product context (vision, mission, personas and JTBD, design guidelines and brand tone of voice) and architectural (system documentation structured following the arc42 framework). Inside arc42 we use C4 to draw the architecture diagrams for each section, and ADRs to populate the dedicated decisions section (§9). None of these frameworks are novel on their own. What’s novel is that we’re not updating them after implementing a new change, we use them as context to write the spec for agents.
Vision, mission, brand, personas and JTBD, design guidelines and brand tone of voice. The company’s identity and direction: who it’s for, why it exists, how it presents itself. The Product Manager agent reads these before scoping a feature, and stress tests the proposed work against strategic pillars and current usage data. Work that doesn’t align with any pillar surfaces immediately as a conversation, not as something that quietly sneaks into a sprint.
System documentation following arc42. Stakeholders, quality goals, system decomposition, technology decisions, risks, and a shared glossary. The Architect agent reads the relevant sections before proposing any spec. arc42 is a free, open-source template that’s been around for over a decade. We adopted it because it gave us a structure we didn’t need to invent.
Diagrams in C4. arc42 calls for architecture diagrams in several sections; we draw ours using C4. It visualizes systems at four levels of detail (Context, Containers, Components, Code). Each level gives agents a map at the right zoom level: broad enough to understand boundaries, precise enough to understand business rules. We render the diagrams as Mermaid in markdown so they live next to the prose and version-control cleanly.
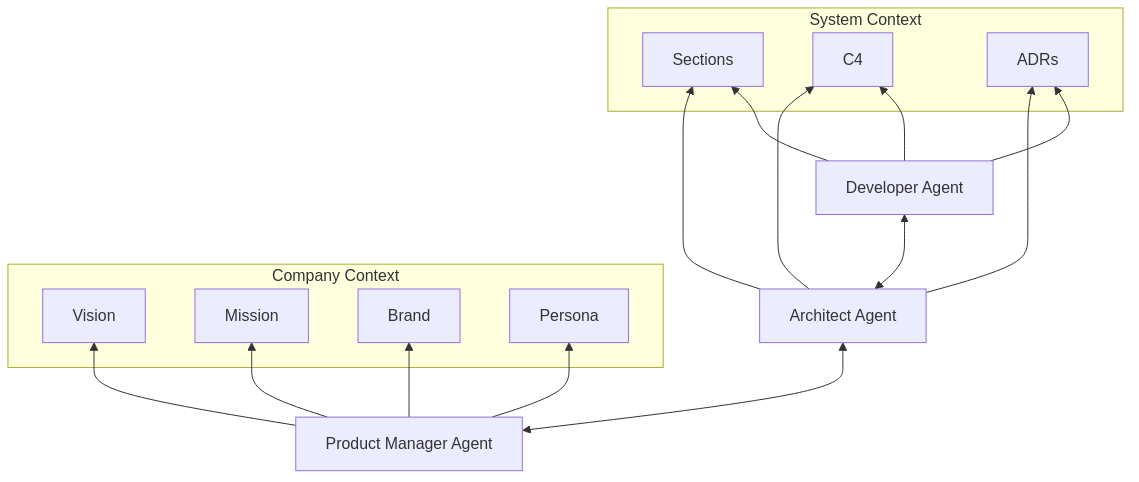
Of these formats, ADRs are the one that pays off most often. Most "AI hallucinations" we see in the wild aren’t really hallucinations. They’re decisions an agent made because nothing told it which way had already been chosen. An ADR collapses that ambiguity to a citation.
What this looks like in practice
A recent feature: a notification system to re-engage users after install.
Our human PM opened a session with the Product Manager agent. They worked through whether to build it (alignment with strategy and vision), what notifications triggers to build in which order, what success looked like (specific engagement metrics). The Architect agent reviewed feasibility against the existing architecture. The Developer agent explored the backend for existing event hooks that could trigger notifications. The session produced an ADR on the notification service choice, an update to the building block view, and three glossary entries.
From that spec, the Project Manager agent broke the work into Linear issues. Each issue referenced the relevant arc42 sections, the new ADR, and the acceptance criteria the PM session had defined.
When implementation began, the developer pasted the first issue’s URL into the tool. The agent read the issue, loaded the referenced arc42 sections and ADR, and applied the patterns defined in our shared rules. It wrote code that matched the conventions on the first pass. The code reviewer agent flagged one error-handling inconsistency on review; the developer agent fixed it. The PR merged.
We don’t have clean apples-to-apples comparison data, but features that used to take a day or more now routinely ship in an afternoon. More importantly, they ship in a state we don’t have to argue about: they follow the conventions we already documented. This eventually means less debates and re-work during pull request review.
The new failure mode: context debt
This isn’t free. We’ve replaced one kind of debt with another.
Technical debt used to cause bugs and decrease velocity. Now it also confuses agents and can introduce more tech debt. When the codebase has inconsistent patterns, agents don’t know which to follow. They pick one, and if it’s the wrong one, the team spends hours unwinding an implementation that went sideways. Tech debt is paid twice: once in defects and a second time when planning the next move.
The new form of debt is context debt: documentation that’s stale, incomplete, or ambiguous. It compounds the same way technical debt does.
There’s one extra propagation path: one agent’s hallucination, once written into a section or an ADR, becomes the next agent’s source of truth.
The honest version of "documentation-first development" is that drift is now visible (agents make bad specs). Even though it’s now easier than ever to maintain documentation thanks to AI and automation pipelines, it still requires a lot of focus and critical thinking to maintain the context infrastructure. During each session it’s about recognising missing or wrong context and creating tasks to improve the central hub so we don’t have to repeat ourselves next time.
What we don’t know yet
Three months in, four people, a greenfield project. The limits we know about:
Scale is unproven. This workflow works at four but will probably need to be re-structured for a bigger team.
Greenfield helps. We had no legacy documentation to retrofit. Applying this to a ten-year-old codebase is a fundamentally different problem.
The cost of staying current. Right now we can maintain the documentation because drift is visible. If team pace increases, the maintenance burden could compound faster than we can absorb it.
We’re sharing what we learned because the direction seems clear, not because we’re certain it scales. The bottleneck was never typing speed. Code was rationed, and we mistook the rationing for the work. The work is shared understanding, built by humans, together.
Next in this series, in two weeks: Agentic Product Management. If documentation is the foundation, what does the layer above look like? What changes about product management when refinement happens with agents in the room?
 | A guest post by
|